1) Data Wrangling or Data Munging
Data wrangling is the process of cleaning and unifying complex datasets for easy access and analysis. Data wrangling is the process typically includes converting and mapping data from its raw form to another format with the purpose of making the data more valuable and appropriate for the advance process such as data analysis and machine learning. sometimes data wrangling is also called data munging.
2)Different types of data:
Data types are divided into two types: Categorical and numerical
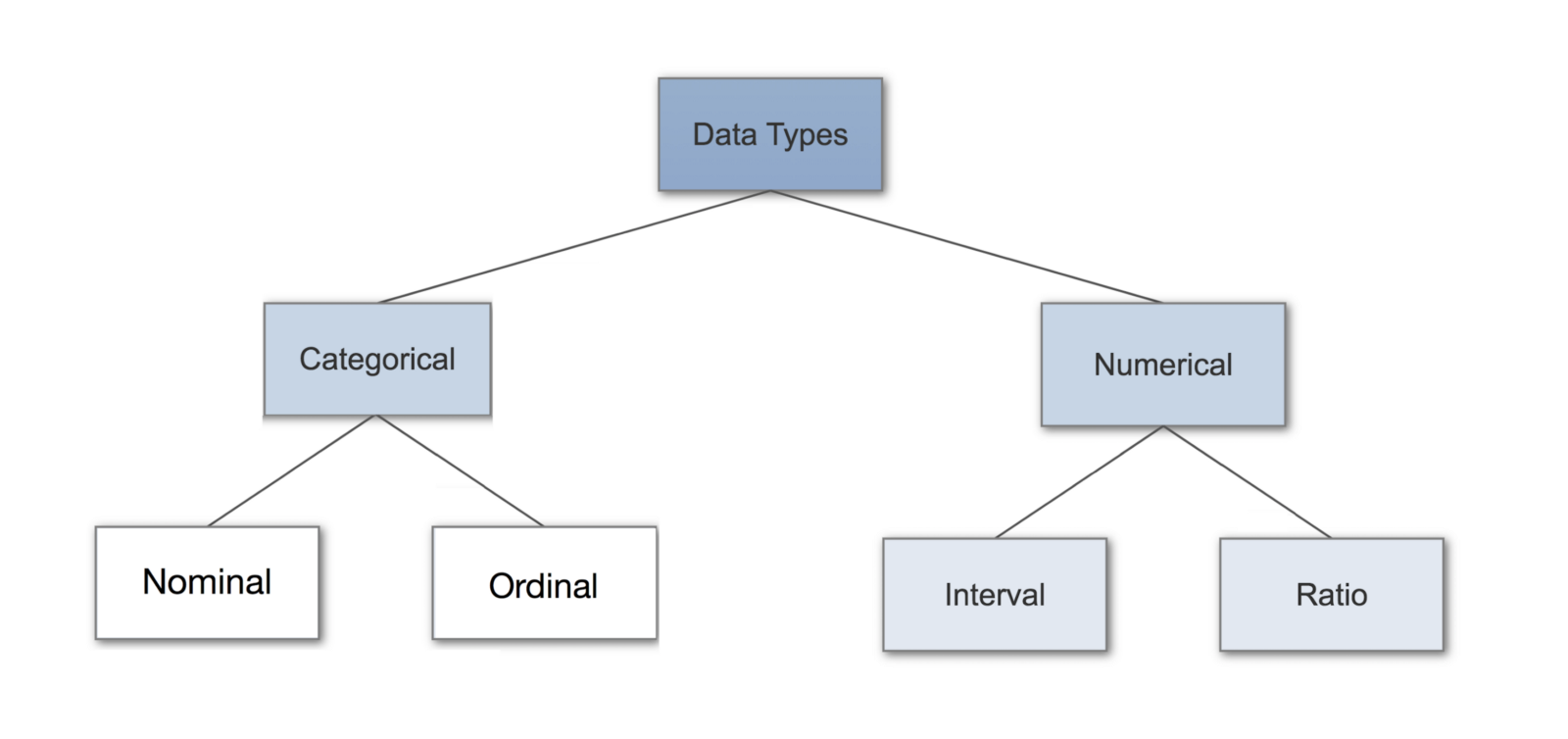
2.1)Categorical data
A data is said to be categorical when numbers are collected as a group or category. Categorical data is also called qualitative data. The categorical data is further classified into two types unordered (nominal) and ordered(ordinal).
Nominal data
A nominal data is one that has two or more categories but there is no intrinsic ordering of categories (ie. Unordered data). An example of nominal data is marital status(single, married, separated).
Ordinal data:
Ordinal data provide good information about the order of values. An example of ordinal data is rating or feedback.
2.2)Numerical data:
Numerical data is data that is measurable, such as height, weight, money and so. Numerical data is also called quantitative data. Numerical data are further classified into interval and ratio.
Interval:
Interval data always appear in the form of numbers where the distance between the two points is standardized and equal. Some example of interval scale would be time, temperature(Celsius), etc.
Ratio:
Ratio data have the same properties as interval data with an equal ratio between each data and it has no numerical negative value. Zero is treated as a point of origin. Example of ratio level data includes distance and area.
3)Types of data collection:
Data collection is the process of collecting information from all the sources to find the answers to the research problem, test the hypothesis and evaluate the outcomes. Data collection is of two categories primary and secondary.
3.1)Primary data collection:
Primary data collection method can be divided into two types: quantitative and qualitative
Quantitative data collection method:
Methods of quantitative data collection and analysis include questionnaires with closed-ended questions, methods of correlation and regression, mean, mode and median and others. Quantitative methods are cheaper to apply and they can be applied within a shorter duration of time compared to qualitative methods.
Qualitative data collection method:
This method does not involve any numbers or mathematical calculations. Qualitative studies aim to ensure a greater level of depth of understanding and qualitative data collection methods include interviews, questionnaires with open-ended questions, focus groups, observation, game or role-playing, case studies, etc.
3.2)Secondary data collection:
Secondary data is a type of data that has already been published or collected by someone else. For example books, government census report, administrative data, etc.
4)Data sources:
A data source is a name given to the connection set up to a database from a server. Databases are the most traditional kind of data source in Business Intelligence. Common database used today includes SQL,MySQL,Oracle,etc.
Three types of Resources:
• Primary sources are original materials on which other research is based.
• Secondary sources are those that describe or analyze primary sources.
• Tertiary sources are those used to organize and locate secondary and primary sources.
5)Data quality issues:
Some common data related quality issues faced by analysts and organizations in general are:
Inconsistent data:
When dealing with multiple data sources, inconsistency is the big indicator that there is a data quality problem. If the system has inconsistent data, then the system used to store or analyze data may not interpret it correctly.
Incomplete data:
Usually, data are not entered in the system correctly, or certain files may have been corrupted. For example: If the address is entered without the zip code, then the rest of the details takes only a little value.
Duplicates:
The same record existing multiple times in a database is called duplicates. Duplicate is one of the biggest problems that exist for data-driven businesses and can bring down revenue faster than any other data issues.
Poorly defined Data:
Often data is poorly defined which causes great confusion around the proper methodology for management. For example, Data is sectioned into a wrong category like a company account being filed as a single person contact, Is going to really mess things up in your database and maker whole thing very difficult to understand.
System upgrade:
Every time the data management system upgrade or hard disk upgrade, there is a chance for losing the data. making a several back up may and upgrading only through the authenticated source is always advisable